- HR:+91-879-9184-787
- Sales:+91-908-163-7774

Artificial Intelligence (AI) and machine learning (ML) have made significant strides in recent years, with supervised learning being one of the foundational techniques driving their success. As a subset of machine learning, supervised learning has been instrumental in developing intelligent systems that can predict, classify, and make decisions based on data.
In this article, we’ll explore what supervised learning is, how it works, and delve into the most commonly used supervised learning algorithms and examples. Additionally, we’ll also examine how it differs from unsupervised learning and its applications in real-world AI systems. If you’re looking to build a custom AI solution, hire AI developers to help implement supervised learning algorithms effectively.
Supervised learning is one of the most widely used machine learning (ML) techniques in artificial intelligence (AI). It is a method of training an algorithm on labeled datasets that contain both input features and the corresponding correct output. The purpose of supervised learning is for the algorithm to learn the relationship between the inputs and outputs so that it can accurately predict or classify new, unseen data.
In simpler terms, supervised learning involves “teaching” a machine to make predictions or decisions based on examples provided by human experts. These examples, often called training data, serve as a guide that allows the machine to learn how to map inputs (e.g., images, text, numbers) to the correct output (e.g., labels, categories, numerical values).
We call this technique supervised because the learning process is akin to a teacher supervising a student, guiding the student with labeled examples and correcting their mistakes until the student learns to predict the correct answers independently.

In supervised learning, the training dataset is composed of labeled examples, meaning each data point comes with the correct answer. For instance, in an email spam filter, the training data might consist of emails labeled as either “spam” or “not spam.” The machine uses this data to learn the patterns that distinguish spam emails from non-spam ones.
The learning process involves feeding the labeled data into a machine learning algorithm. During this phase, the model tries to find the underlying pattern or relationship between the input data (e.g., features like email subject, sender, content) and the output labels (spam or not spam). The model adjusts its parameters to minimize the error in its predictions by comparing the predicted output to the actual output in the training data.
Once the model is trained, it is tested using a separate set of unseen data to evaluate how well it generalizes to new examples. This testing phase ensures that the model can make accurate predictions or classifications when it encounters data that it has never seen before.
After training and testing, the model can be used to make predictions on new data, which may not have labels. In other words, the model applies what it has learned during training to new, unlabeled inputs and produces outputs based on the patterns it discovered during the training phase.
Supervised learning is a critical aspect of machine learning, where an algorithm is trained on labeled data to learn patterns and relationships between inputs and outputs. Based on the type of prediction task, supervised learning in AI can be classified into two major categories: regression and classification. Both categories are used for solving different kinds of problems, and each comes with its own set of algorithms and techniques.
In this section, we’ll delve into the two primary types of supervised learning, regression and classification, and explore their specific applications and methods in greater detail.

Regression is used in supervised learning when the output variable is a continuous value. Essentially, regression models aim to predict numerical values based on input data. For example, predicting a house’s price based on features like square footage, number of rooms, and location is a typical regression problem.
Linear regression is the simplest and most commonly used algorithm for regression tasks. It tries to model the relationship between input variables (features) and the target variable (output) using a straight line.
Formula: y=mx+cy = mx + cy=mx+c, where yyy is the dependent variable, mmm is the slope, xxx is the independent variable, and ccc is the intercept.
Example: Predicting a car’s price based on attributes like age, make, and mileage.
Polynomial regression is an extension of linear regression, where the relationship between the dependent and independent variables is modeled as an nth degree polynomial.
It is useful when the data shows a non-linear relationship.
Example: Predicting the growth of a population over time where the data follows a curved pattern.
Ridge regression is a regularized version of linear regression that addresses the issue of multicollinearity by adding a penalty term to the cost function. It helps prevent overfitting by discouraging large coefficients in the model.
Example: Predicting house prices where many independent variables are correlated.
Lasso regression is another regularized version of linear regression that selects features by shrinking some coefficients to zero, effectively eliminating less relevant features from the model.
Example: Predicting student performance based on multiple features, where some features may not contribute significantly to the outcome.
Classification is used when the output variable is a categorical label, meaning the algorithm predicts which category or class the input data belongs to. For example, predicting whether an email is spam or not spam, or whether a tumor is malignant or benign, are both classification problems.
Logistic regression is used for binary classification tasks where the goal is to assign an input to one of two categories.
Example: Classifying emails as spam or not spam.
It estimates the probability that a given input belongs to a certain class (usually using a sigmoid function).
Decision trees split the data into subsets based on feature values, building a tree-like structure where each node represents a feature or attribute, and branches represent decision rules.
Example: Predicting whether a loan application will be approved based on features like income and credit score.
Random forests are ensembles of decision trees that improve accuracy by averaging the predictions of multiple trees. This reduces the overfitting problem that decision trees often face.
Example: Classifying whether an image contains a cat or a dog based on pixel values.
SVM is a powerful classification algorithm that finds the hyperplane that best separates different classes. It is effective in high-dimensional spaces.
Example: Classifying handwritten digits from the MNIST dataset.
K-NN is a simple classification algorithm that classifies data based on the majority class of its K nearest neighbors in the feature space.
Example: Classifying products as high demand or low demand based on historical sales data.
Naive Bayes is based on Bayesian probability and assumes that the features are conditionally independent given the class label. It is widely used for text classification tasks.
Example: Sentiment analysis on customer reviews (classifying as positive or negative sentiment).
Neural networks, especially deep learning models, are used for complex classification tasks involving large datasets, like image recognition, speech recognition, and natural language processing.
Example: Classifying objects in images as a car, tree, dog, etc.
While supervised learning requires labeled data for training, unsupervised learning in AI works with unlabeled data, where the model tries to find patterns or clusters without predefined output labels.
Supervised learning is one of the fundamental techniques used in machine learning (ML) and artificial intelligence (AI). In this learning process, a model is trained on labeled data—data that includes both input features and their corresponding correct output labels. By learning from this data, the model is able to make predictions or classifications based on new, unseen data.
To fully understand how supervised learning works, let’s break it down step by step, starting from the data collection process to how the trained model makes predictions.
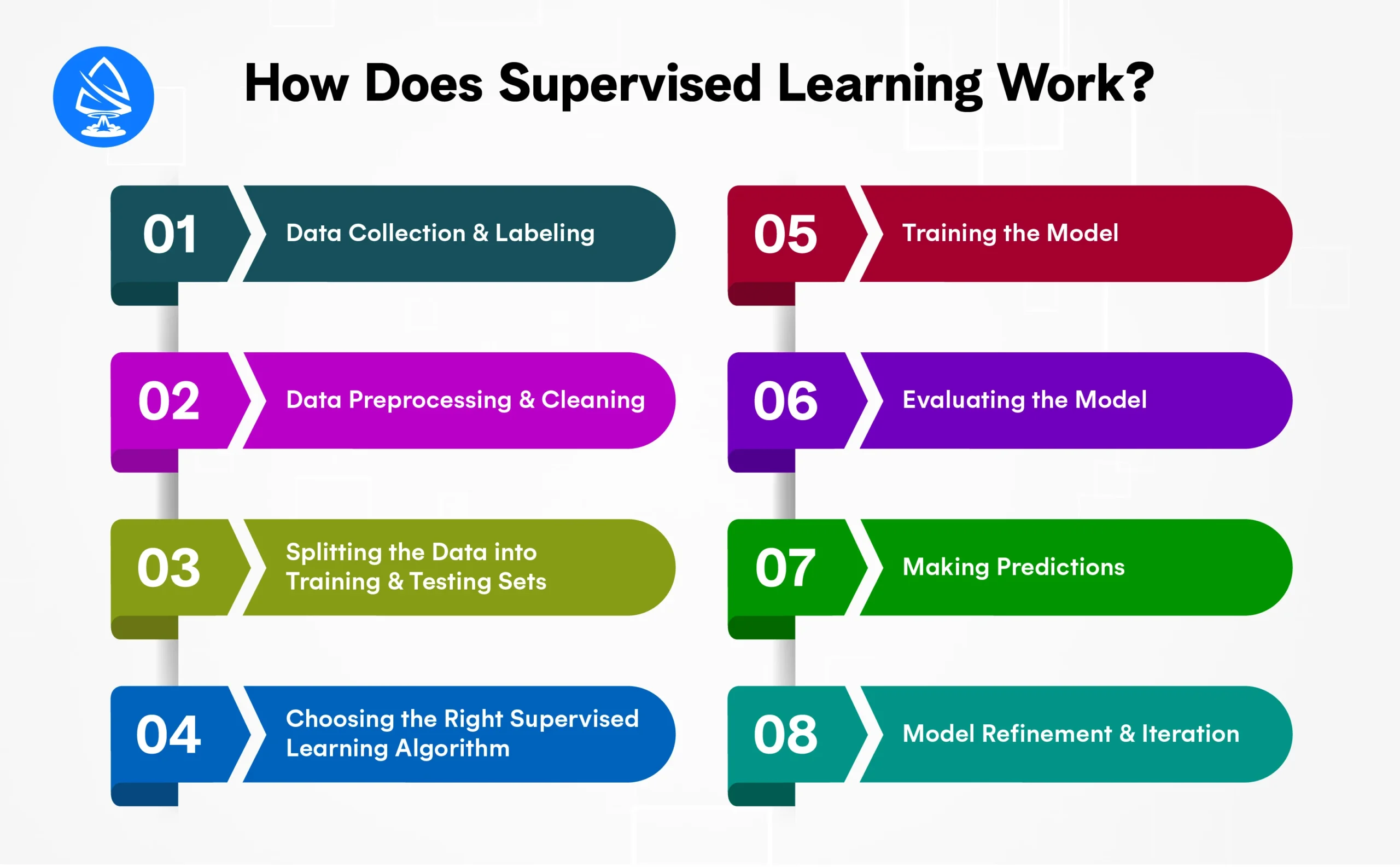
The first step in the supervised learning in AI process is collecting and labeling data. This is a critical step, as the model will only be as good as the data it is trained on. The data collected for training must be labeled, meaning that each data point should have an associated output that corresponds to the correct result or class.
Once the data is collected, it is often preprocessed and cleaned to make it suitable for training the model. This step is essential to ensure that the data is free from inconsistencies and irrelevant features.
The next step is to divide the dataset into two parts:
A common practice is to split the data into 70% for training and 30% for testing, though other ratios can also be used (e.g., 80/20).
Once the data is prepared, the next step is to choose an appropriate supervised learning algorithm to train the model. The choice of algorithm depends on the type of problem you’re trying to solve, whether it’s a regression or classification task, the nature of the data, and how accurate you want the model to be.
The algorithm is chosen based on the problem at hand, and it will be responsible for learning patterns in the training data.
Training the model involves feeding the training data into the chosen algorithm so that it can learn the relationship between the inputs and their corresponding outputs. During this phase, the model makes predictions based on the input data, and its predictions are compared to the actual output labels.
The learning process is iterative, with the model adjusting its parameters to reduce the error in its predictions. This is done using an optimization technique like gradient descent, which helps minimize the loss function, a measure of how far off the model’s predictions are from the actual outputs.
After training the model, it’s important to evaluate its performance on the testing data that the model hasn’t seen before. This step helps assess how well the model generalizes to new, unseen examples.
The model’s performance on the test set helps determine if it is overfitting (performing well on training data but poorly on test data) or underfitting (not performing well on either training or test data).
Once the model trains and evaluates, it becomes ready to make predictions on new, unseen data. In this final step, you use the model to apply what it has learned during the training phase to solve real-world problems.
If the model is trained on email data, it can now classify incoming emails as spam or non-spam based on its learned understanding from the training data.
In regression tasks, the model can predict numerical values, such as the price of a house or the expected sales revenue for the next quarter.
In many cases, the first version of the model may not be perfect. If the performance is not satisfactory, the model can be refined by:
It is an iterative process, and the model’s performance can continue to improve with ongoing adjustments.
Supervised learning employs a variety of algorithms to make predictions or classifications. Below are some of the most commonly used supervised learning algorithms:

Linear regression is a statistical method used for regression tasks where the goal is to predict a continuous value. It models the relationship between the independent variables (input features) and the dependent variable (output).
Example: Predicting housing prices based on features like square footage, location, and number of bedrooms.
Despite the name, logistic regression is used for classification tasks, where the goal is to assign data to a particular class. It predicts the probability that an input belongs to a certain class (typically binary).
Example: Classifying whether an email is spam or not spam.
A decision tree is a flowchart-like tree structure where each internal node represents a feature or attribute, each branch represents a decision rule, and each leaf node represents an output label.
Example: Classifying whether a loan application will be approved based on factors like income, credit score, etc.
SVM is a supervised learning algorithm used for both classification and regression tasks. It works by finding the hyperplane that best separates data into classes.
Example: Classifying handwritten digits or identifying whether a customer is likely to churn.
The K-NN algorithm classifies data points based on the majority class of the K nearest neighbors in the feature space. It is a simple but powerful algorithm.
Example: Classifying types of flowers based on petal and sepal measurements (e.g., Iris dataset).
A random forest is an ensemble method that uses multiple decision trees to make predictions. Each tree is trained on a random subset of the data, and the final prediction is made based on the majority vote.
Example: Predicting customer satisfaction based on features like purchasing behavior, demographics, etc.
While supervised learning uses labeled data for training, unsupervised learning works with unlabeled data, where the model tries to identify patterns or relationships within the data on its own.
Example of Supervised Learning: Predicting whether a customer will churn (labeled data with known customer outcomes).
Example of Unsupervised Learning: Segmenting customers into groups based on purchasing behavior (no labels on groups).
Let’s take a simple example of supervised learning in AI with a classification problem:
You have a dataset of emails, where each email is labeled as either spam or not spam. You want to train a model that can classify new emails as spam or not spam.
Supervised learning is a foundational technique in the field of artificial intelligence and machine learning, where algorithms learn from labeled data to make predictions or classifications. It’s an essential tool for solving many real-world problems, from email spam detection to predicting house prices. The supervised learning algorithms covered, including linear regression, decision trees, and support vector machines, are commonly applied across industries for predictive modeling and classification tasks. If you’re looking to integrate these techniques into your project, partnering with an artificial intelligence app development company can help you create tailored solutions.
As AI continues to advance, supervised learning models will play a critical role in developing smarter systems capable of understanding patterns in data, making decisions, and improving business operations. Understanding supervised learning in AI and how to apply it effectively is crucial for those looking to enter the world of AI or enhance their current machine learning applications.
Supervised learning is a type of machine learning where the algorithm is trained on labeled data, with the aim of predicting outputs for new, unseen data.
Supervised learning uses labeled data for training, while unsupervised learning uses unlabeled data and tries to identify patterns or structures within the data.
Yes, supervised learning can be used for both classification (e.g., categorizing emails as spam or not spam) and regression (e.g., predicting house prices based on features).
Examples include linear regression, logistic regression, decision trees, random forest, and support vector machines (SVM).
The algorithm learns from labeled data, maps input features to the corresponding output, and then uses this learned model to make predictions on new data.
We widely use supervised learning for spam detection, image recognition, speech recognition, and predicting future trends (e.g., stock market prediction).
Supervised learning requires a large amount of labeled data, which can be time-consuming and expensive to acquire. It also struggles with overfitting if the model is too complex.
As you feed more labeled data into the system and fine-tune models, the accuracy and predictive power of supervised learning models improve, leading to better outcomes.
Artoon Solutions
Artoon Solutions is a technology company that specializes in providing a wide range of IT services, including web and mobile app development, game development, and web application development. They offer custom software solutions to clients across various industries and are known for their expertise in technologies such as React.js, Angular, Node.js, and others. The company focuses on delivering high-quality, innovative solutions tailored to meet the specific needs of their clients.
Copyright 2009-2025

