Large Language Models (LLMs) are at the forefront of AI and Natural Language Processing (NLP). These powerful models have transformed the way machines understand and generate human language. From enhancing chatbots to driving innovations in machine translation and content creation, LLMs are playing a pivotal role in the AI landscape. If you want to implement LLMs effectively, you can hire AI developers to ensure that your AI solutions are built to the highest standards.
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a type of artificial intelligence (AI) model specifically designed to process and understand human language. These models are based on deep learning architectures, particularly neural networks, that are trained on vast amounts of text data. The term “large” refers to the massive scale of the model, both in terms of the amount of data it processes and the number of parameters it contains. LLMs are an essential component in many AI-driven applications such as chatbots, content generation, translation systems, and more.
Key Components of a Large Language Model
Data-driven Learning:
LLMs are trained on enormous datasets that contain diverse human-written text. This data often includes books, articles, websites, and other written forms of communication. The model learns from the patterns in this text, such as grammar, word relationships, sentence structure, and even the nuances of context and meaning. The larger the dataset, the better the model can generalize across various tasks.
Transformer Architecture:
One of the foundational architectures behind LLMs is the transformer architecture. Introduced by Vaswani et al. in 2017, transformers revolutionized the way AI models process sequential data. Unlike older models that processed data word by word, transformers process entire sequences of words simultaneously, allowing the model to capture long-range dependencies and context across sentences. This is made possible by self-attention mechanisms, which let the model focus on relevant parts of the input text as it makes predictions.
Parameters and Model Size:
The power of LLMs comes from the massive number of parameters they contain. Parameters are the internal settings that the model learns during training to make predictions. A single LLM can have billions or even trillions of parameters. For example, GPT-3 has 175 billion parameters, enabling it to understand and generate complex language patterns with high accuracy. The large number of parameters allows the model to capture intricate relationships between words, phrases, and concepts.
Unsupervised Learning:
LLMs are primarily trained using unsupervised learning, meaning they do not require labeled data to learn. Instead, the model is exposed to a large corpus of text and learns to predict the next word in a sentence based on the preceding context. This method of learning allows the model to develop an understanding of language structure and meaning without needing direct human annotations.
Generative Capabilities:
One of the defining features of LLMs is their generative capability, meaning they can generate coherent and contextually appropriate text based on input. Given a prompt or a partial sentence, an LLM can predict the next words or even generate entire paragraphs. This makes them highly effective for tasks like content creation, automated writing, and summarization.
Chatbots and Virtual Assistants: LLMs power many modern chatbots and virtual assistants like Siri, Alexa, and Google Assistant. These systems rely on LLMs to understand user queries, process the language, and generate appropriate responses in real-time.
Machine Translation: LLMs are also the backbone of translation systems such as Google Translate. By processing vast amounts of bilingual data, LLMs can learn how to translate text from one language to another, maintaining context and meaning.
Content Generation: Tools like GPT-3 are capable of generating human-like text based on a prompt. This is used in applications ranging from automated blog writing and code generation to poetry and creative writing.
Sentiment Analysis and Text Classification: LLMs can analyze text data to determine the sentiment behind it (positive, negative, neutral) and classify text into different categories. This is used for customer feedback analysis, social media sentiment analysis, and more.
Question Answering Systems: LLMs are trained to answer questions based on a given text, making them useful for creating intelligent FAQ systems, customer service bots, and even automated research assistants.
Limitations of LLMs
Despite their powerful capabilities, LLMs come with certain limitations:
Data Bias: Since LLMs are trained on data that includes human-written text, they can inherit biases present in that data. For example, if the training data contains biased language or stereotypes, the LLM may also replicate those biases in its outputs.
Context and Memory: While LLMs excel at understanding language patterns, they may struggle with maintaining long-term context across extended conversations or large bodies of text. This can limit their ability to engage in deep or multi-turn dialogues.
Resource Intensive: Training an LLM is computationally expensive and requires massive amounts of data and processing power. This means that only a few companies and organizations with substantial resources can afford to develop and train these models.
Dependence on Training Data: The performance of an LLM is heavily dependent on the quality and diversity of the training data. If the data is lacking in certain areas or contains inaccuracies, the model may produce flawed or unreliable outputs.
How Do Large Language Models (LLMs) Work?
Large Language Models (LLMs) are at the heart of many advanced AI systems that process and generate human language. These models are designed to understand and produce language by leveraging complex architectures, vast amounts of training data, and sophisticated learning methods. The core functionality of LLMs relies on deep learning, especially the transformer architecture, which enables them to excel at a wide range of Natural Language Processing (NLP) tasks. Here’s a detailed breakdown of how LLMs work:
1. The Transformer Architecture
The most common architecture used in modern LLMs is the transformer. Introduced in the paper “Attention is All You Need” by Vaswani et al. in 2017, transformers marked a significant advancement in how AI models process sequences of data. Unlike earlier models like Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, transformers process all parts of the input text simultaneously, rather than sequentially. This allows them to capture long-range dependencies and contextual information more effectively.
The key components of a transformer include:
Self-attention mechanism: This is the core idea behind the transformer model. Self-attention allows the model to weigh the importance of different words in a sentence when making predictions. For instance, in the sentence “The cat sat on the mat,” the word “cat” is more relevant to understanding the sentence than the word “on.” Self-attention helps the model focus on the relevant words by calculating attention scores.
Multi-head attention: Instead of focusing on just one aspect of the relationship between words, multi-head attention allows the model to capture multiple relationships in parallel. This enables the model to understand different contexts or meanings that words can take depending on their position in a sentence.
Positional encoding: Since transformers do not process data sequentially, they use positional encodings to represent the position of words in a sentence. These encodings help the model understand the order of words, which is crucial for interpreting the meaning of the text correctly.
2. Training Process and Data Input
LLMs are trained on massive datasets that contain vast amounts of human-written text. This training process typically involves the following steps:
Pre-training: In the pre-training phase, the LLM learns to predict the next word in a sentence or phrase. This is done through unsupervised learning, meaning the model is not explicitly told what the correct output is for every input but learns to make predictions based on patterns it observes in the data. For example, given the phrase “The cat sat on the ___,” the model learns to predict that “mat” is a likely next word. This helps the model learn the structure and patterns of human language, including grammar, syntax, and even some contextual meanings.
Fine-tuning: After pre-training, the LLM is often fine-tuned on specific tasks, such as text classification, sentiment analysis, or machine translation. Fine-tuning involves training the model on a smaller, task-specific dataset, helping it adapt to the nuances of the task and perform well on real-world applications.
The training data for LLMs often comes from diverse sources such as books, websites, academic papers, and more. The more diverse and extensive the dataset, the better the model becomes at generalizing to different types of language and tasks.
3. Model Parameters and Layers
LLMs are characterized by their massive number of parameters. A parameter is a setting in the model that is adjusted during the training process to help the model make better predictions. These parameters can be thought of as knobs that are fine-tuned to capture patterns in the data. The more parameters an LLM has, the more complex relationships it can capture.
For example:
GPT-3 has 175 billion parameters, which allows it to generate highly coherent and contextually accurate text based on a given prompt.
GPT-4 further increases the number of parameters, enhancing its ability to handle even more complex tasks.
An LLM’s neural network is made up of multiple layers. Each layer consists of nodes that compute and transform the input data. The depth of the network (i.e., the number of layers) allows the model to learn increasingly abstract representations of language. As the data passes through each layer, the model identifies more complex relationships and patterns, allowing it to generate sophisticated outputs.
4. Learning Techniques and Optimization
The learning process for LLMs involves adjusting the model’s parameters to minimize the difference between the model’s predictions and the actual outcomes. This is done using a method called gradient descent.
Gradient Descent: In simple terms, gradient descent is a mathematical optimization technique used to find the best possible parameters for the model. The model starts with random parameters, makes predictions, compares them to the actual outputs, and then adjusts the parameters based on the error. This process is repeated iteratively to gradually improve the model’s performance.
Backpropagation: This is the process through which the model adjusts its parameters based on the error. The error is propagated backward through the network, and each layer’s parameters are updated accordingly to minimize the overall error.
5. Language Understanding and Generation
Once trained, LLMs can perform a wide range of tasks, depending on the specific application. Some of the key capabilities of LLMs include:
Language Understanding: LLMs can understand context, recognize relationships between words, and even grasp subtleties such as sarcasm or ambiguity. This is particularly useful in tasks like sentiment analysis, question answering, and named entity recognition.
Language Generation: One of the standout features of LLMs is their ability to generate human-like text. Given a prompt or a starting sentence, the model can continue generating coherent, contextually relevant text. This capability is utilized in applications like automated content creation, chatbots, and even creative writing.
Translation: LLMs can also be used for machine translation, translating text from one language to another while maintaining meaning and context.
6. Transfer Learning in LLMs
An important concept in LLMs is transfer learning, which allows the model to be fine-tuned for different tasks after pre-training on a large dataset. For example, a model like BERT can be pre-trained on general language data and then fine-tuned for specific tasks like text classification or sentiment analysis. This ability to transfer knowledge from one domain to another is one of the reasons why LLMs are so effective at handling a wide variety of NLP tasks.
7. Inference and Deployment
Once trained, LLMs can be deployed in various applications. The inference process involves feeding new data into the trained model to generate predictions or outputs. For example, in a conversational AI system, the model takes user input (such as a question) and generates an appropriate response.
Latency and Efficiency: While LLMs can generate highly accurate outputs, they are computationally expensive. This makes it essential to optimize models for inference, ensuring that they can generate responses quickly and efficiently in real-time applications like chatbots or virtual assistants.
Types of Large Language Models (LLMs)
Large Language Models (LLMs) are a broad category of artificial intelligence (AI) models designed to process and generate human language. Over time, multiple types of LLMs have emerged, each with unique architectures and capabilities tailored for different natural language processing (NLP) tasks. These models vary based on their structure, training methods, and use cases. Here’s a detailed exploration of the types of Large Language Models (LLMs):
1. Autoregressive Models
Autoregressive models are designed to predict the next word or token in a sequence, based on the context of the preceding words. These models generate text sequentially, one token at a time, and at each step, they consider the words that have come before it to predict the next one. This characteristic makes autoregressive models particularly useful for text generation tasks, where coherence and continuity across sentences are essential.
Key Characteristics:
Sequential Generation: The model generates text step-by-step, considering the previous words to predict the next one.
Focus on Output Generation: Primarily used for tasks such as text completion, dialogue systems, and creative writing.
One-directional: The model processes input from left to right (or right to left in some cases), making it ideal for language generation but less suitable for tasks that require bidirectional context.
Example Models:
GPT-3 and GPT-4: These are prime examples of autoregressive models. GPT (Generative Pre-trained Transformer) is trained on vast amounts of text data and is capable of generating human-like text based on a given prompt. GPT models excel at a wide range of language tasks, from conversational agents to code generation.
Applications:
Text generation
Creative writing (stories, poems, etc.)
Dialogue systems
Code generation
2. Encoder-Decoder Models
Encoder-decoder models are used for tasks where the input and output sequences have a one-to-one relationship, such as in machine translation or text summarization. These models are often called seq2seq models (sequence-to-sequence) because they transform one sequence into another.
The architecture consists of two parts:
Encoder: This part processes the input sequence (e.g., a sentence in the source language). It compresses the sequence into a vector representation, capturing all relevant information.
Decoder: The decoder takes this compressed representation and generates an output sequence (e.g., the translation of the sentence into a target language).
Key Characteristics:
Bidirectional Context: Unlike autoregressive models, encoder-decoder models are able to understand context from both sides of the input sequence (left and right) due to their bidirectional encoding.
Translation and Transformation Tasks: Typically used for tasks where input needs to be converted into a corresponding output sequence.
Example Models:
T5 (Text-to-Text Transfer Transformer): This model uses an encoder-decoder framework and is designed for a wide variety of text-related tasks. T5 can be fine-tuned for tasks like summarization, translation, question answering, and more.
BART: A model combining both autoregressive and encoder-decoder methods, it is highly effective for text generation and denoising tasks (e.g., text completion or summarization).
Applications:
Machine translation
Text summarization
Question answering
Text transformation
3. Bidirectional Models
Bidirectional models are designed to understand language from both directions (left-to-right and right-to-left). This is especially useful for tasks that require context from the entire sentence, such as question answering or text classification, where knowing both the preceding and following words in a sentence is crucial for correct understanding.
Key Characteristics:
Bidirectional Context: Unlike autoregressive models that only consider previous context, bidirectional models use both past and future context to understand the meaning of words more effectively.
Non-sequential: These models process the entire input at once, allowing them to capture more global patterns and relationships in the data.
Example Models:
BERT: BERT is one of the most famous bidirectional models. It processes text in a way that allows it to understand the full context of a word in a sentence, regardless of its position. BERT is pre-trained using a masked language model, where random words in a sentence are replaced with a mask, and the model has to predict the masked word based on the surrounding context.
RoBERTa: A variant of BERT, RoBERTa improves upon the original model by using larger training data and optimizing hyperparameters for better performance.
Applications:
Sentiment analysis
Text classification
Question answering
Named entity recognition (NER)
4. Hybrid Models
Hybrid models combine features from both autoregressive and encoder-decoder architectures. They aim to leverage the strengths of both approaches, making them highly versatile for a wide range of tasks.
Key Characteristics:
Combined Strengths: By combining autoregressive and encoder-decoder capabilities, these models can excel at both generative tasks (like text generation) and tasks that require understanding and transformation of input (like summarization or translation).
Flexible for Multiple Tasks: These models are often designed to be more general-purpose, capable of performing a wide range of tasks without needing specialized training for each.
Example Models:
T5 (Text-to-Text Transfer Transformer): T5 is a prime example of a hybrid model that can handle various NLP tasks. It treats all tasks as text-to-text problems (e.g., “Translate English to French” or “Summarize this article”).
BART: Combining the autoregressive and encoder-decoder frameworks, BART excels in tasks like text generation and denoising, which require both encoding and decoding capabilities.
Applications:
Text generation
Text summarization
Question answering
Translation
5. Retrieval-Augmented Models
These models combine language generation with external knowledge retrieval systems. They are designed to improve the performance of LLMs by allowing them to access and incorporate external information that wasn’t part of their original training data.
Key Characteristics:
External Knowledge: Retrieval-augmented models pull information from external databases or documents to enrich their responses. This allows them to answer questions or generate text that involves facts or specific data not included in their training set.
Dynamic Content Generation: These models are capable of generating more informed and accurate outputs by referencing up-to-date information.
Example Models:
REALM (Retrieval-Augmented Language Model): REALM integrates a retrieval mechanism into the pre-training of LLMs, allowing them to query an external knowledge source (such as a database) during training to improve performance on tasks requiring factual accuracy.
RAG (Retrieval-Augmented Generation): RAG combines the power of retrieval (searching through external data sources) with generation (creating text based on this retrieved information), making it suitable for tasks such as open-domain question answering.
Applications:
Question answering with external knowledge
Fact-based content generation
Real-time data access for text generation
6. Multimodal Models
Multimodal models are a newer class of LLMs that are designed to process multiple types of input, such as text, images, and videos, simultaneously. These models aim to combine language understanding with other sensory data to create more comprehensive AI systems that can perform complex tasks requiring both vision and language.
Key Characteristics:
Multimodal Inputs: These models are trained on datasets that include multiple types of data (e.g., text with images), allowing them to understand and generate outputs that involve both text and visual content.
Integrated Language and Vision: Multimodal models can generate text descriptions of images, answer questions about visual content, and even generate images from textual descriptions.
Example Models:
CLIP (Contrastive Language-Image Pretraining): CLIP is designed to understand images and text together, enabling tasks like image classification based on textual prompts or generating textual descriptions of images.
DALL·E: DALL·E is a multimodal model that can generate images from textual descriptions, combining the power of language understanding with image generation.
Applications:
Image captioning
Text-to-image generation
Visual question answering
Training Large Language Models
Training an LLM requires massive computational resources. It involves feeding large datasets into the model, followed by iterative optimization through techniques like gradient descent. The training process also requires fine-tuning on specific tasks, such as text summarization, sentiment analysis, or question answering, to adapt the model for practical use cases.
Given the size of these models, LLM training can take weeks or even months and requires distributed computing across thousands of GPUs or TPUs. As a result, only a few organizations, often backed by substantial computational power, can afford to train these models from scratch.
LLM Benchmarks and Performance Metrics
Evaluating LLMs requires various benchmarks to measure their effectiveness across different language tasks. Some common LLM benchmarks include:
GLUE (General Language Understanding Evaluation): Measures the model’s performance on tasks like question answering, textual entailment, and sentiment analysis.
SuperGLUE: An extension of GLUE that challenges models with more difficult tasks.
SQuAD (Stanford Question Answering Dataset): Used to test a model’s ability to answer questions based on context.
These benchmarks provide a standardized way to compare different LLMs and gauge their accuracy, efficiency, and real-world applicability.
Applications of Large Language Models (LLMs)
Large Language Models (LLMs) have revolutionized the field of artificial intelligence (AI), making significant strides in natural language processing (NLP) and deep learning. The power and versatility of LLMs have led to their application across a wide array of industries, from customer service to healthcare, entertainment, and beyond. Their ability to understand and generate human language in a coherent and contextually relevant manner allows them to perform tasks that were once difficult or even impossible for machines. Below, we explore the various key applications of LLMs in detail:
1. Chatbots and Virtual Assistants
One of the most widely recognized applications of LLMs is in the development of chatbots and virtual assistants. These systems leverage the power of LLMs to interact with users in a natural, human-like way.
How It Works:
Contextual Understanding: LLMs process user input, considering not only the specific words but also the broader context of the conversation. This enables chatbots to provide more relevant and coherent responses, as they can understand the nuances of user intent.
Natural Conversations: By using models like GPT-3 or BERT, virtual assistants can handle a variety of tasks such as answering questions, providing recommendations, and carrying out commands.
Examples:
Siri, Google Assistant, Amazon Alexa: These virtual assistants use LLMs to understand and respond to voice commands, helping users manage their tasks, get weather updates, control smart devices, and more.
Customer Support Chatbots: Many businesses deploy LLM-based chatbots to handle customer inquiries, resolve issues, and provide support 24/7.
Applications:
Customer service
Personal assistant tasks (setting reminders, sending messages)
Information retrieval (answering questions, web search)
2. Content Generation
LLMs excel at generating human-like text, which makes them ideal for a wide variety of content creation tasks. They can produce articles, blog posts, product descriptions, social media posts, scripts, and more with little or no human intervention.
How It Works:
Text Generation: By analyzing vast datasets during training, LLMs learn how to generate coherent and contextually appropriate text. For instance, given a prompt like “Write a blog post about AI in healthcare,” the model will generate an article that is informative, well-structured, and relevant.
Creative Writing: LLMs can also be used for more creative tasks like writing stories, poetry, and even songs. This has opened new avenues for content creators in entertainment, marketing, and media.
Examples:
GPT-3: Known for its ability to generate complex and meaningful content, GPT-3 is frequently used for automatic blog writing, news article generation, and ad copy creation.
AI Content Tools: Tools like Copy.ai, Writesonic, and Jarvis (formerly Jasper) use LLMs to assist marketers in generating high-quality content faster.
Applications:
Automated article and blog post writing
Product descriptions for e-commerce
Scriptwriting and creative writing
Marketing copy (social media posts, advertisements)
News generation
3. Sentiment Analysis
Sentiment analysis involves determining the emotional tone behind a body of text, helping businesses gauge customer feelings and opinions. LLMs are highly effective in this area because they can process large amounts of unstructured text and determine whether it expresses positive, negative, or neutral sentiment.
How It Works:
Contextual Understanding: LLMs consider not just individual words but their context in the sentence. For example, the word “great” has a positive sentiment in most contexts, but in a sarcastic context, it may convey the opposite.
Text Classification: LLMs classify text into sentiment categories based on patterns they have learned from training data.
Examples:
Social Media Monitoring: LLMs are used by brands to monitor public sentiment on platforms like Twitter, Facebook, and Instagram.
Customer Feedback Analysis: Companies use sentiment analysis to analyze customer reviews, survey responses, and emails to gauge customer satisfaction and improve services.
Applications:
Brand reputation management
Market research and consumer insights
Customer feedback analysis
Social media sentiment analysis
4. Machine Translation
Machine translation is one of the earliest and most impactful applications of LLMs, enabling the automatic translation of text between different languages. With the use of LLMs, translation systems have become more accurate and contextually aware.
How It Works:
Bidirectional Understanding: Models like BERT and T5 utilize bidirectional processing to understand context in both languages simultaneously, ensuring more accurate translations.
Contextual Translation: LLMs consider the broader context of a sentence or paragraph rather than translating word by word, which allows for more fluent and natural translations.
Examples:
Google Translate: Powered by LLMs, it supports translation between numerous languages and is continually improving its capabilities.
DeepL: Known for its superior translation quality, DeepL leverages LLMs to produce contextually accurate translations.
Applications:
Multilingual communication and document translation
Content localization for global markets
Cross-language customer support
International business operations
5. Text Summarization
Text summarization is the process of condensing a large body of text into a shorter, more digestible version while preserving the main ideas. LLMs can perform extractive summarization (selecting important sentences) and abstractive summarization (generating new sentences that convey the core message).
How It Works:
Extractive Summarization: The model selects sentences or passages that are most relevant to the main idea of the text.
Abstractive Summarization: The model generates new sentences that capture the essence of the original content but may use different wording or phrasing.
Examples:
GPT-3 and T5: These models can generate concise summaries for long documents, articles, or research papers.
News Summarizers: LLM-based tools are used by news agencies to generate summaries of lengthy articles, making it easier for readers to stay informed.
Applications:
Automatic summarization of news articles and reports
Summarizing legal documents, research papers, or academic journals
Shortened content for busy readers
Summarizing customer service chats for analysis
6. Question Answering (QA) Systems
Question Answering systems use LLMs to provide answers to users’ questions by retrieving relevant information from a text corpus. These systems are used in search engines, virtual assistants, and customer support chatbots.
How It Works:
Information Retrieval: The LLM first processes the input question, then identifies relevant information from a dataset or document.
Contextual Answer Generation: The model generates an answer based on the available information, ensuring it is contextually appropriate.
Examples:
Google Search: Google uses LLMs to answer direct queries and display concise answers in the search results.
Customer Support Chatbots: These systems leverage LLMs to understand customer questions and provide accurate, context-aware responses.
Applications:
Virtual assistants and conversational AI
Customer support and helpdesk automation
Information retrieval and search engines
Educational tools and online learning platforms
7. Healthcare and Medical Research
LLMs have also found applications in healthcare, particularly in medical research, diagnosis support, and patient care. By processing large volumes of medical literature and patient records, LLMs can assist in identifying new insights, automating documentation, and enhancing decision-making.
How It Works:
Medical Text Analysis: LLMs analyze medical records, research papers, and clinical notes to extract relevant information, such as disease patterns, treatment recommendations, and drug interactions.
Clinical Decision Support: LLMs assist healthcare providers by suggesting diagnoses or treatment options based on patient data and medical guidelines.
Examples:
IBM Watson for Health: Watson uses LLMs to analyze medical data and provide actionable insights for diagnosis and treatment.
Clinical Documentation Assistance: LLMs help healthcare professionals with the documentation of patient visits and electronic health records (EHR).
Applications:
Medical text mining and literature analysis
Clinical decision support systems (CDSS)
Automated documentation and transcription
Predictive models for disease outbreaks and healthcare trends
Best Large Language Models (LLMs)
Large Language Models (LLMs) have become the backbone of many advanced artificial intelligence (AI) systems, transforming how machines process and understand human language. Over the years, various LLMs have been developed, each excelling in specific tasks or domains. Here’s a detailed look at some of the best LLMs in the field, highlighting their strengths, capabilities, and applications:
1. GPT-3 (Generative Pre-trained Transformer 3)
Developer: OpenAI Released: June 2020 Size: 175 billion parameters
Overview:
GPT-3 is one of the largest and most well-known autoregressive language models developed by OpenAI. It has 175 billion parameters, making it one of the most powerful LLMs to date. It can perform a wide range of natural language tasks without the need for task-specific training data, relying on few-shot learning where only a few examples are needed for the model to perform a given task.
Key Features:
Natural Language Generation (NLG): GPT-3 can generate human-like text based on a prompt, from short sentences to full articles, essays, and even poetry.
Flexibility: It can perform tasks such as text generation, translation, summarization, and question answering without fine-tuning on specific datasets.
Zero-Shot and Few-Shot Learning: The model performs well on new tasks with little to no additional training data, making it extremely versatile.
Applications:
Text generation (articles, stories, poetry)
Code generation
Chatbots and conversational agents
Question answering and summarization
Why It’s One of the Best:
GPT-3’s ability to perform a broad array of tasks with minimal fine-tuning is unparalleled. Its diverse capabilities, coupled with the impressive scale of 175 billion parameters, make it one of the most robust and widely used LLMs.
2. GPT-4 (Generative Pre-trained Transformer 4)
Developer: OpenAI Released: March 2023 Size: Estimated at 500 billion+ parameters (exact number not disclosed)
Overview:
GPT-4 is an even more advanced version of GPT-3 and represents the next step in OpenAI’s series of LLMs. With an estimated 500 billion parameters (or more), GPT-4 has significantly improved in accuracy, contextual understanding, and versatility. It builds on GPT-3’s architecture while incorporating enhanced features such as multimodal input (text and image) processing, allowing it to generate and understand both text and images.
Key Features:
Enhanced Contextual Understanding: GPT-4 can handle more complex and nuanced queries, producing more accurate and coherent results.
Multimodal Capabilities: GPT-4 can process both text and images, enabling richer, more complex tasks such as generating captions for images or interpreting visual data alongside text.
Greater Accuracy: GPT-4 is better at handling rare or ambiguous queries and produces fewer hallucinated (inaccurate) results compared to GPT-3.
Applications:
Multimodal applications (text and image understanding)
Content creation (text, captions, and visual data integration)
Virtual assistants
Complex decision-making tasks
Why It’s One of the Best:
GPT-4’s ability to process multiple forms of input and produce highly accurate, contextually relevant outputs makes it one of the most advanced LLMs to date. Its multimodal capabilities open up new possibilities for AI applications in areas such as healthcare, education, and e-commerce.
3. BERT (Bidirectional Encoder Representations from Transformers)
Developer: Google AI Released: October 2018 Size: 340 million parameters (for base model)
Overview:
BERT is one of the most influential LLMs in the field of Natural Language Understanding (NLU). Unlike autoregressive models like GPT, BERT is a bidirectional model, meaning it processes the entire context of a sentence rather than generating words from left to right. This enables BERT to understand relationships between words more effectively and capture the nuances of context in a sentence.
Key Features:
Bidirectional Processing: BERT looks at the entire sentence to understand context, making it especially effective for tasks like sentiment analysis, named entity recognition (NER), and question answering.
Masked Language Model: During training, BERT randomly masks words in a sentence and learns to predict them based on the surrounding context. This pre-training method enables it to excel in downstream tasks.
Fine-tuning: BERT can be fine-tuned for a wide range of specific NLP tasks, achieving state-of-the-art results in many benchmarks.
Applications:
Question answering (e.g., Google’s search engine)
Named entity recognition (NER)
Sentiment analysis
Text classification
Why It’s One of the Best:
BERT’s bidirectional approach, which provides a deeper understanding of text, has set new standards for many NLP tasks. Its fine-tuning capabilities and impressive performance on benchmarks like GLUE and SQuAD have solidified its position as one of the best LLMs for natural language understanding.
4. T5 (Text-to-Text Transfer Transformer)
Developer: Google Research Released: 2019 Size: 11 billion parameters (for the largest model)
Overview:
T5 is a transformer-based model designed to unify all NLP tasks into a text-to-text framework. Unlike models that are specialized for a particular task (e.g., translation or summarization), T5 treats every NLP problem as a text generation task. For example, text classification is treated as “Classify this text as [label]” and summarization is framed as “Summarize this text.”
Key Features:
Text-to-Text Framework: This unification allows T5 to handle a wide range of tasks, such as summarization, translation, question answering, and classification, with the same architecture.
Versatility: By reframing tasks as text generation, T5 is able to handle many NLP challenges with a single model, which simplifies deployment and scaling.
Pre-trained on Massive Data: T5 is pre-trained on a large corpus of text data, including diverse types of text from multiple domains.
Applications:
Text summarization
Machine translation
Question answering
Text classification
Paraphrasing
Why It’s One of the Best:
T5’s ability to generalize across multiple tasks using a unified text-to-text format makes it one of the most versatile models. Its flexibility and impressive performance across various NLP benchmarks have made it a go-to solution for many real-world applications.
5. RoBERTa (Robustly Optimized BERT Pretraining Approach)
Developer: Facebook AI Released: 2019 Size: 355 million parameters (base model)
Overview:
RoBERTa is a variant of BERT that improves upon the original by optimizing the pretraining process. It was designed by Facebook AI to overcome some of the limitations in BERT’s training and fine-tuning procedures. RoBERTa removes BERT’s next-sentence prediction task and uses much larger mini-batches and more data to achieve superior performance.
Key Features:
Optimization of BERT’s Pretraining: RoBERTa achieves higher performance by optimizing hyperparameters, removing unnecessary tasks (like next-sentence prediction), and using more data.
Enhanced Performance: RoBERTa outperforms BERT on several NLP benchmarks, including GLUE and SuperGLUE, demonstrating its robustness.
Applications:
Text classification
Sentiment analysis
Question answering
Text generation
Why It’s One of the Best:
RoBERTa’s refined training process allows it to outperform BERT on a variety of tasks, making it one of the top choices for high-performance NLP applications.
6. BART (Bidirectional and Auto-Regressive Transformers)
Developer: Facebook AI Released: 2019 Size: 406 million parameters (base model)
Overview:
BART is another advanced LLM developed by Facebook AI, combining the best of BERT and autoregressive models. It works by encoding input text with a bidirectional transformer and then decoding it using an autoregressive approach. BART is particularly effective for tasks that require a combination of understanding and generating text, such as text generation and summarization.
Key Features:
Hybrid Architecture: By combining the strengths of BERT’s bidirectional encoder and the autoregressive decoder, BART can generate high-quality text based on a deeper understanding of input data.
Denoising Autoencoder: During pre-training, BART is trained to reconstruct corrupted text, making it robust for generation tasks.
Applications:
Text generation
Text summarization
Translation
Paraphrasing
Why It’s One of the Best:
BART’s hybrid nature allows it to excel at tasks that require both understanding and generating text, making it one of the most powerful models for content creation, summarization, and more.
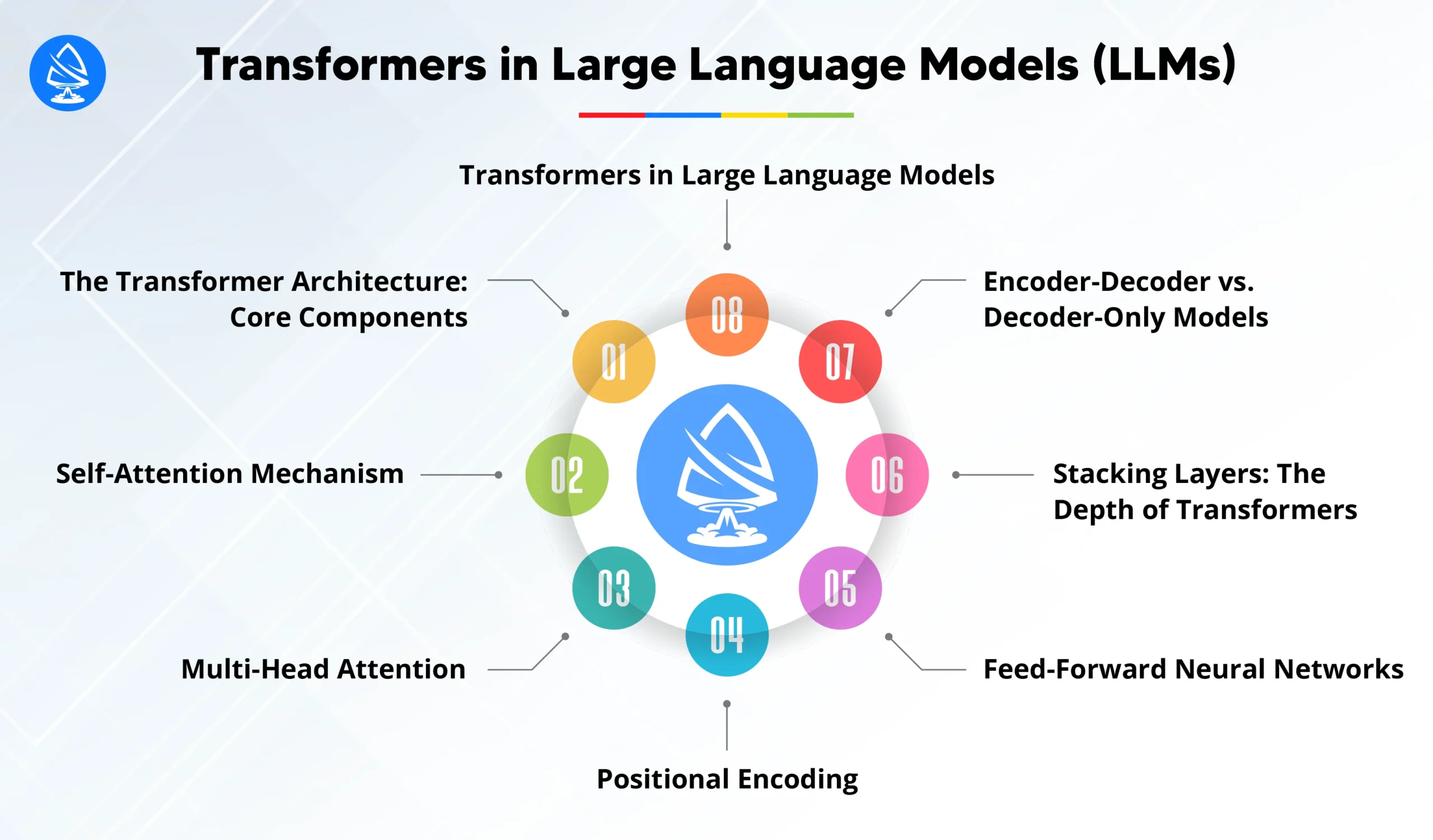
Transformers in Large Language Models (LLMs)
Transformers have revolutionized the field of natural language processing (NLP) and are the backbone of most modern Large Language Models (LLMs). Introduced by Vaswani et al. in 2017 in their seminal paper “Attention is All You Need,” the transformer architecture has become the dominant framework for building state-of-the-art language models. Unlike previous architectures, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), transformers handle sequences of data much more efficiently and effectively, making them ideal for tasks like text generation, translation, and understanding.
Below, we break down the key aspects of transformers and explain why they are critical to the success of LLMs.
1. The Transformer Architecture: Core Components
Transformers consist of two main parts: the encoder and the decoder. These components work together to process and generate sequences of text, but not all transformer models use both. For instance, models like BERT use only the encoder, while models like GPT (Generative Pre-trained Transformer) use the decoder.
Encoder
The encoder is responsible for processing input text and extracting relevant features. It consists of multiple layers of self-attention and feed-forward neural networks that help the model understand and represent the context in a text.
Decoder
The decoder is used in models that generate output sequences, such as GPT or T5. It takes the encoder’s output and generates the final sequence, predicting the next word or token in the sequence.
2. Self-Attention Mechanism
At the heart of transformers is the self-attention mechanism, which allows the model to focus on different parts of the input sequence simultaneously, rather than processing it sequentially (as in RNNs or LSTMs). Self-attention is the process of weighing the importance of each word in a sentence relative to the others. It enables the model to capture long-range dependencies and relationships between words, regardless of their position in the sentence.
How Self-Attention Works:
For each word in the input sequence, the model computes three vectors:
Query (Q): Represents the word the model is currently focusing on.
Key (K): Represents the words that the model compares to the current word.
Value (V): Contains the actual information from the words.
The model calculates a similarity score (attention score) between the query and key, and then uses this score to weight the value of each word. This allows the model to understand the importance of each word in context, even if they are far apart in the sequence.
Benefits of Self-Attention:
Capturing Long-Term Dependencies: Unlike RNNs and LSTMs, which process text sequentially, transformers can capture long-range dependencies, making them more efficient at understanding complex relationships between words.
Parallelization: Self-attention allows transformers to process all words in a sequence at once (in parallel), significantly improving computational efficiency. This is a major advantage over RNNs, which process data one step at a time.
Scalability: The self-attention mechanism is highly scalable and can handle much longer sequences of text than RNNs or LSTMs, which are prone to vanishing gradient problems as sequences grow longer.
3. Multi-Head Attention
The concept of multi-head attention builds upon the idea of self-attention. Instead of calculating a single attention score, multi-head attention runs multiple self-attention processes in parallel, each with a different learned representation. The outputs of these attention heads are then concatenated and passed through a linear layer.
Benefits of Multi-Head Attention:
Capturing Different Aspects of Context: Each attention head can focus on different aspects of the input sequence, allowing the model to capture various relationships and nuances.
Increased Expressiveness: By combining the outputs of multiple attention heads, the model can express more complex patterns and relationships in the data.
4. Positional Encoding
Since transformers process all words in a sequence simultaneously, they do not inherently capture the order of the words (unlike RNNs or LSTMs, which process words sequentially). To address this, transformers use positional encodings to inject information about the position of each word in the sequence.
How Positional Encoding Works:
Positional encodings are added to the input embeddings (word representations) to inform the model about the position of words within the sequence. This allows the transformer to differentiate between words that appear at different positions in a sentence. The positional encoding is usually implemented as a vector that is added to the embedding of each word.
Benefits of Positional Encoding:
Capturing Word Order: This mechanism enables the transformer to understand the order of words in a sentence, which is crucial for tasks like translation and sentence generation.
Flexibility: Positional encoding allows transformers to work with variable-length sequences, making them adaptable to a wide range of NLP tasks.
5. Feed-Forward Neural Networks
After the self-attention mechanism, each encoder and decoder layer in a transformer includes a feed-forward neural network (FFN), which applies transformations to the attention output. These networks consist of two fully connected layers with a ReLU activation function in between. FFNs allow the model to capture complex relationships and refine the output representation.
Benefits of Feed-Forward Networks:
Non-linearity: The inclusion of the ReLU activation introduces non-linearity, which enables the model to learn more complex patterns and relationships in the data.
Dimension Expansion and Reduction: FFNs increase and decrease the dimensionality of the data, allowing the model to manipulate information effectively and build richer representations.
6. Stacking Layers: The Depth of Transformers
A key characteristic of transformers is their depth. Both the encoder and decoder consist of multiple layers, often between 6 and 12 for models like BERT and GPT, and as high as 100+ layers for advanced models like GPT-3. Each layer consists of the components we’ve discussed: self-attention, multi-head attention, and feed-forward networks, allowing the model to learn complex representations of language at different levels.
Benefits of Deep Architecture:
Hierarchical Understanding: Each layer in a transformer model learns increasingly abstract representations of the input, allowing the model to capture both low-level features (like word meanings) and high-level features (like sentence structure and context).
Improved Performance: Deeper models tend to perform better on complex NLP tasks, as they can learn richer representations of language.
7. Encoder-Decoder vs. Decoder-Only Models
Encoder-Decoder Models: These models, such as T5 and BART, use both the encoder and decoder parts of the transformer architecture. They are useful for tasks that involve transforming an input sequence into an output sequence, such as machine translation or text summarization.
Decoder-Only Models: Models like GPT-3 and GPT-4 use only the decoder part of the transformer. These models are optimized for tasks that involve generating text based on a given prompt, such as text generation, conversation, and question answering.
8. Transformers in Large Language Models
Transformers are the backbone of nearly all modern LLMs, enabling them to handle complex natural language tasks. The combination of self-attention, multi-head attention, and a deep neural network architecture allows these models to learn rich contextual relationships between words, phrases, and sentences. This makes transformers highly effective at tasks such as:
Text generation
Text classification
Machine translation
Text summarization
Question answering
The ability to process input data in parallel, learn from vast amounts of data, and capture long-range dependencies are the key reasons why transformers are so powerful and have become the architecture of choice for LLMs.
Conclusion
Large Language Models have rapidly transformed the field of artificial intelligence, enabling machines to understand and generate human language in ways previously thought impossible. These models are capable of powering applications across industries, from healthcare to entertainment. As the technology continues to evolve, the potential uses for LLMs are only expanding.
By leveraging LLMs, businesses can enhance customer engagement through AI-driven solutions like chatbots, improve content creation workflows, and even break language barriers with advanced translation systems. For companies looking to explore the potential of Large Language Models, working with an AI development company or hiring AI developers is crucial to unlocking the full capabilities of this transformative technology.
Frequently Asked Questions
1. What are Large Language Models?
Large Language Models (LLMs) are AI models trained on vast datasets to understand and generate human-like language, powering applications like chatbots and content generation.
2. How do Large Language Models work?
LLMs work using transformer-based architectures, employing self-attention mechanisms to process and predict language sequences efficiently.
3. What are the types of Large Language Models?
The main types include autoregressive models (like GPT), encoder-decoder models (like T5), and bidirectional models (like BERT).
4. What is the training process for LLMs?
Training LLMs involves feeding large datasets into the model and optimizing its parameters using techniques like gradient descent across powerful computational infrastructures.
5. What are some examples of Large Language Models?
Prominent examples include GPT-3, BERT, and T5, each excelling in different NLP tasks.
6. What are LLM benchmarks?
Benchmarks like GLUE, SuperGLUE, and SQuAD evaluate LLM performance across various language tasks such as question answering and sentiment analysis.
7. How do LLMs apply to real-world tasks?
LLMs are used in chatbots, content generation, machine translation, and many other AI-driven applications.
Written By :
Artoon Solutions
Artoon Solutions is a technology company that specializes in providing a wide range of IT services, including web and mobile app development, game development, and web application development. They offer custom software solutions to clients across various industries and are known for their expertise in technologies such as React.js, Angular, Node.js, and others. The company focuses on delivering high-quality, innovative solutions tailored to meet the specific needs of their clients.